Star schema
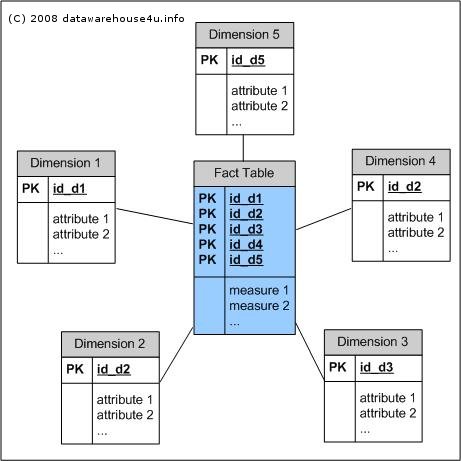
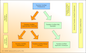
What is star schema? The star schema architecture is the simplest data warehouse schema. It is called a star schema because the diagram resembles a star, with points radiating from a center. The center of the star consists of fact table and the points of the star are the dimension tables. Usually the fact tables in a star schema are in third normal form(3NF) whereas dimensional tables are de-normalized. Despite the fact that the star schema is the simplest architecture, it is most commonly used nowadays and is recommended by Oracle.
Fact Tables
A fact table typically has two types of columns: foreign keys to dimension tables and measures those that contain numeric facts. A fact table can contain fact's data on detail or aggregated level.
Dimension Tables
A dimension is a structure usually composed of one or more hierarchies that categorizes data. If a dimension hasn't got a hierarchies and levels it is called flat dimension or list. The primary keys of each of the dimension tables are part of the composite primary key of the fact table. Dimensional attributes help to describe the dimensional value. They are normally descriptive, textual values. Dimension tables are generally small in size then fact table.
Typical fact tables store data about sales while dimension tables data about geographic region(markets, cities) , clients, products, times, channels.
The main characteristics of star schema:
- Simple structure -> easy to understand schema
- Great query effectives -> small number of tables to join
- Relatively long time of loading data into dimension tables -> de-normalization, redundancy data caused that size of the table could be large.
- The most commonly used in the data warehouse implementations -> widely supported by a large number of business intelligence tools
Data Warehouse schema architecture | Snowflake schema | Fact constellation schema
Further Reading on Star Schema
- Star Schema: Do I Need One for My Data Warehouse? on SQLBot.co - A great, in-depth article on the Star Schema.
Data Warehouse Info











Recently added reviews
Try Xplenty
The ELT Tool Built for the Cloud
The ELT Tool Built for the Cloud
Unlimited Connectors | Unlimited Pipelines | 14 Day Free Trial